AGC014F Strange Sorting を解いた
初期 AGC 屈指の難問として名高い AGC014F Strange Sorting を解いたので解法を残しておきます。 問題を最初に開いてから AC まで軽く 5, 6 年はかかりました
なお、非想定+未証明+ライブラリ殴りの三点セットです。
問題概要
長さ $N$ の順列 $p$ に対して、以下の操作を繰り返す。
- $\max_{1\le j \le i} p_j = p_i$ となる $p_i$ (高い項と呼ぶ)を全て抜き出して、順番は変えずに末尾に追加する
$p$ をソートされた状態にするためには、何回操作を行えばいいか答えよ。
例: $p = (3,5,1,2,4)$
- $(3, 5)$ が条件を満たすため、$p = (1,2,4,3,5) $ に更新
- $(1,2,4,5)$ が条件を満たすため、$p = (3,1,2,4,5)$ に更新
- $(3,4,5)$ が条件を満たすため、$ p = (1,2,3,4,5) $ に更新.よって、3回でソート完了
観察
まず観察してみると以下のようなことが分かる。
- $k$ 回の操作を行うと、必ず末尾 $k$ 項がソート済みとなる(つまり、末尾のほうが徐々にそろっていく)
- また、一度 $i, i+1$ が隣接するとその二項は常に一緒に動く
- $p = (1, 3, 5, 7, 2, 4, 6)$ のようなパターンでは、奇数のブロックが動く -> 偶数のブロックが動く ... を繰り返して、ソートするのに $n$ 回かかるような例を作ることができる(シミュレーションが厳しそうな例)
$p$ 全体を更新するシミュレーションはどうやっても無理そうなので、同時に動くものは一気に動かすようなシミュレーションを考えたくなる。
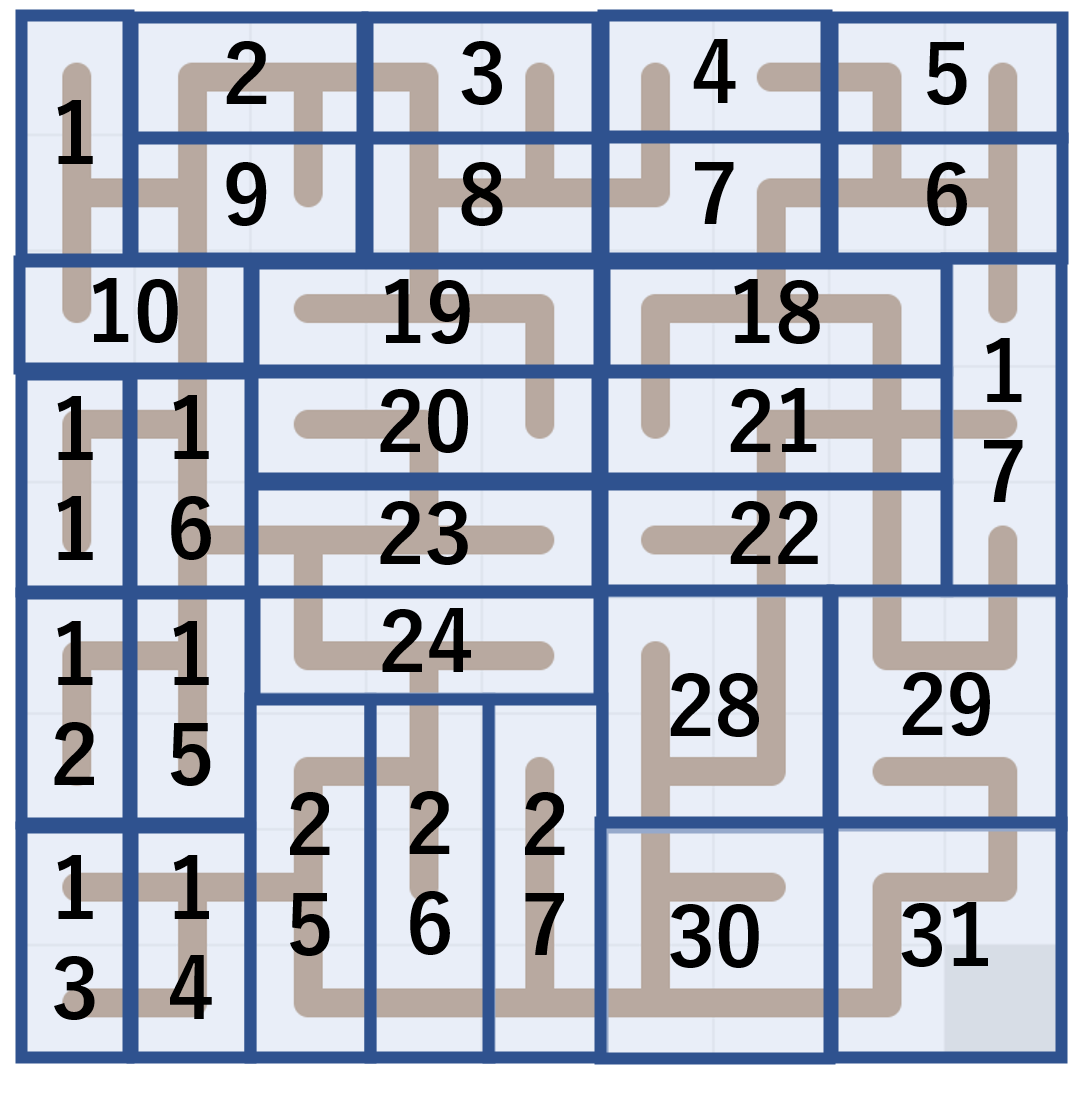
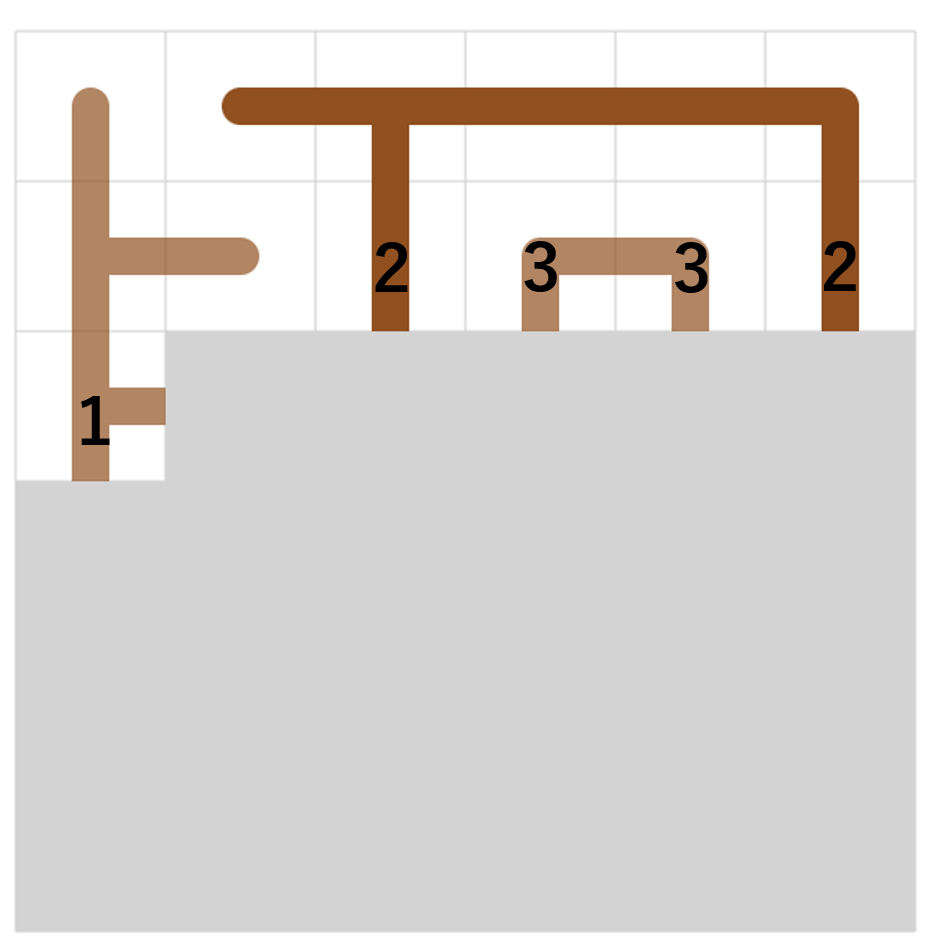
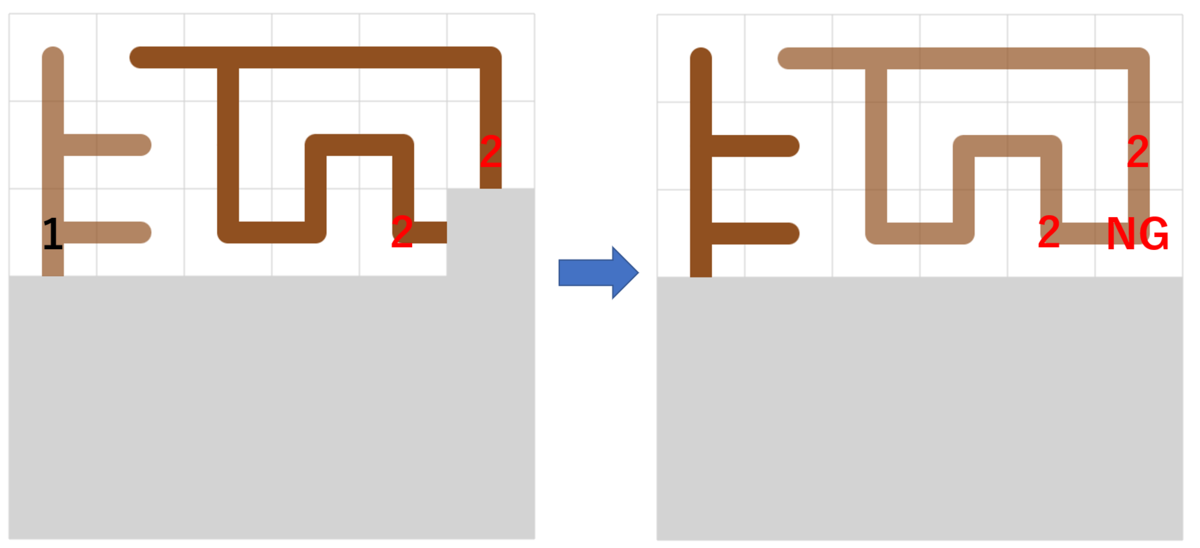
まず $k$ 回目で、高い項となる項のリストの更新を考える。
この時以下のように、更新すると $k$ 回目で高い項となる項のリストを順に計算可能である(図を見た方が分かりやすいかも)。
- 現在 $i-1$ 回目までのリストの処理が終わっているとする。この時 $i$ 回目に高い項が次に高い項となるタイミングを計算する。
- $i$ 回目のリストの末尾の項 $X$ が次に高い項となるタイミングは、その時点での $i+1$ 回目以降のリストの末尾が $X$ より小さい最も早いタイミングになる ($i+1$ 回目移行のリストの末尾は常に単調減少なので、二分探索で見つけることが出来る)
- このとき、$X$ が次に高い項となるタイミングの末尾が$Y < X$ であるとすると、 $Y+1$ 以上 $X$ 以下の値ブロックは同時に動く
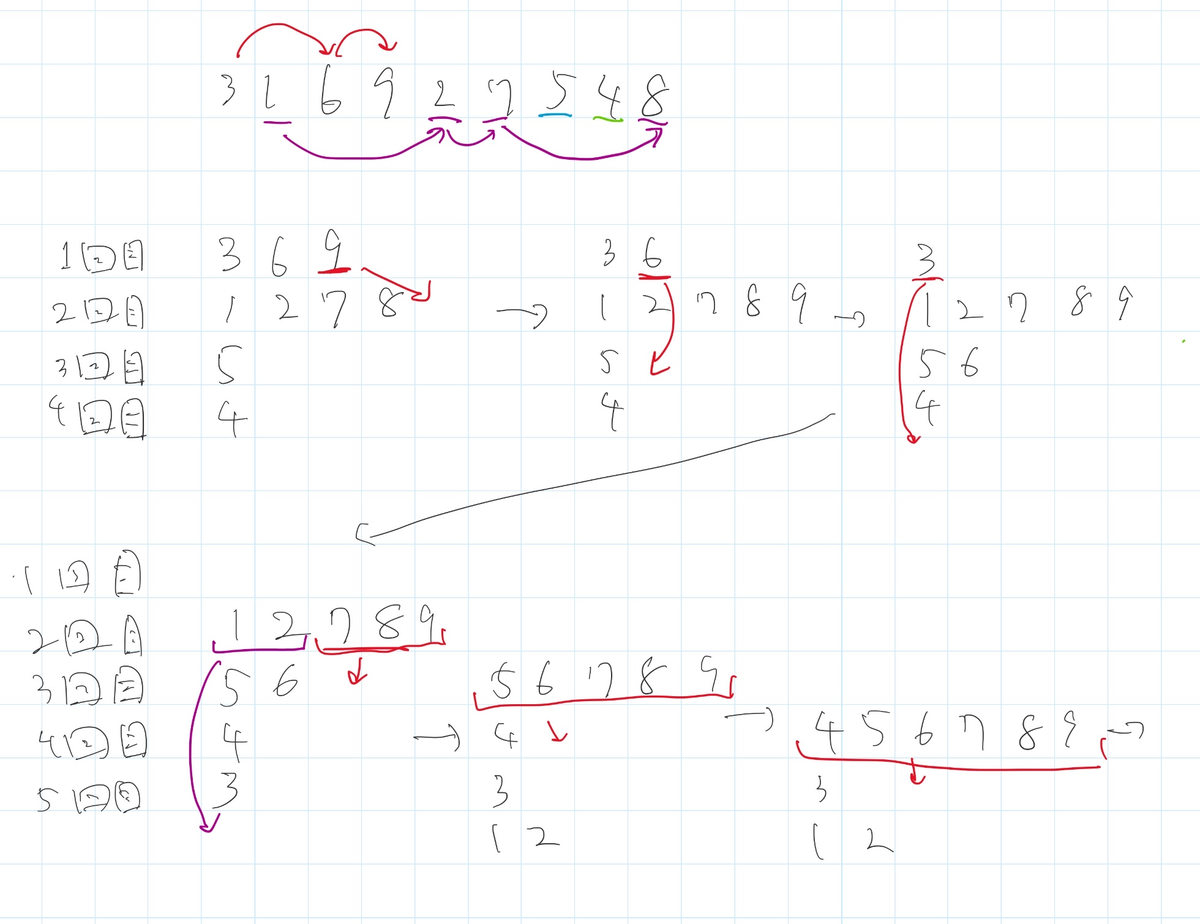
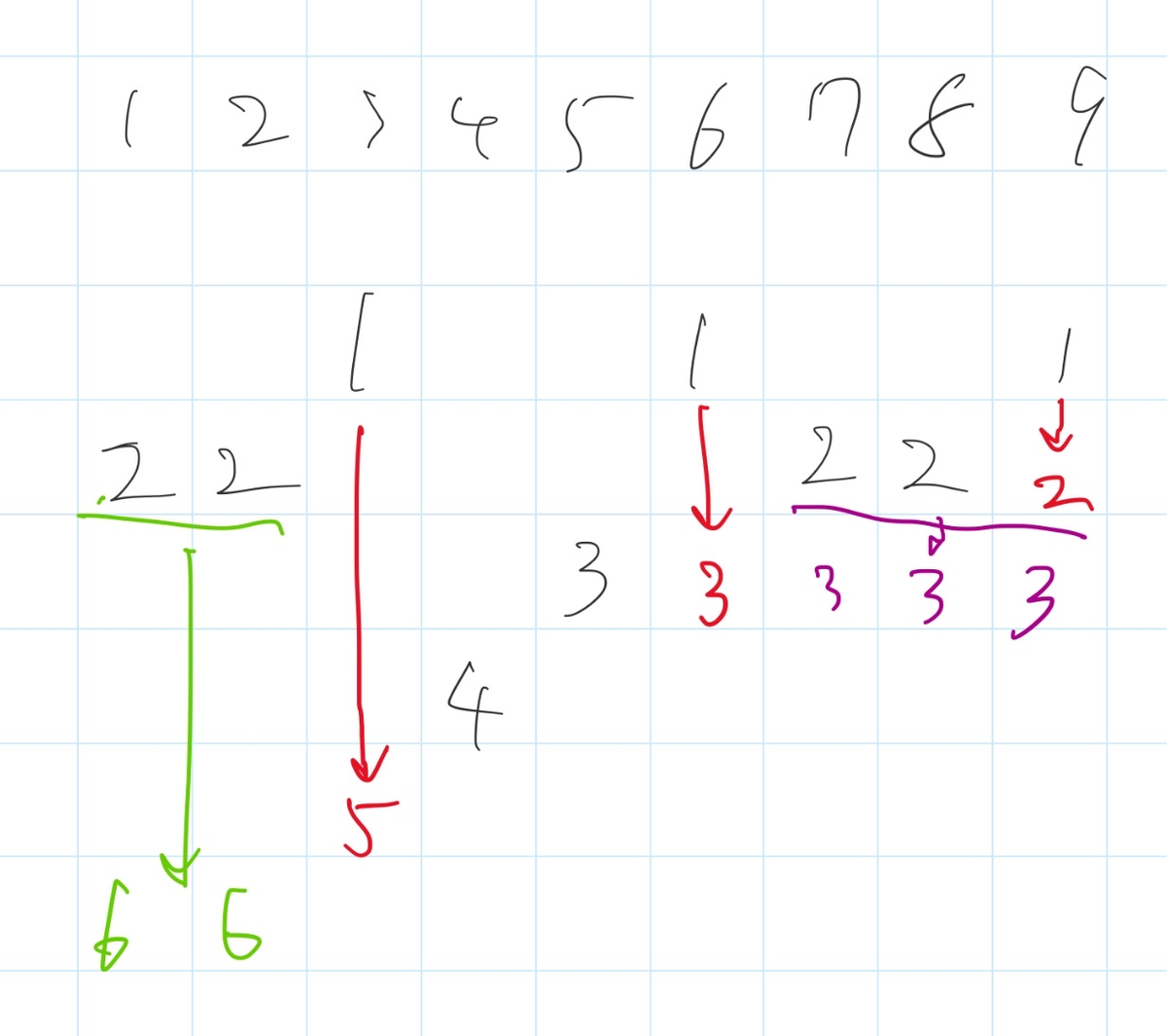
これを、別の表にすると以下の通り。各値が何回目に高い項になるかを書いていくと、非常にそれっぽい更新が見える。(これはかなり想定解の方向に進んでいそうだな~と感じられる。 in-place でこの数列を更新できるか?と考えたくなる)
ゴリ押し
数列の更新の方針を考えたがそこで何も得られなかったので、$k$ 回目に高い項のリストを高速に計算する怪しげな黒魔術の方向に向かった。 (例えば、$p = (1, 3, 5, 7, 2, 4, 6)$ は一項ずつの更新では無理だったが、同時に値をブロックで動かすようにリストを更新出来れば $n$ 回くらいの更新で出来ることから、なかなかこの方針は落とせないんじゃね?という考え(悪巧み)に至った)
このシミュレーションを高速にやる方法を考える。出来れば良い操作は、
- 各リストの末尾の二分探索
- 各リストに対して二分探索
- 各リストの split, join
各数列の末尾は普通に vector で管理すれば二分探索可能。ということで、数列の split, join, 二分探索を同時に行えればよく、これは平衡二分探索木で可能!
kopricky 先生の Treap を使いましょう。
適当なランダムケースを実行したところ、操作回数 133576 回 でリストの更新は 1762199 回となっていた。
更新回数の見積もりが出来ないけど提出!
 AC!終わり!(平衡二分探索木がよく分からなくて、雑に二分探索で log を2個つけたら TLE したのはご愛嬌)
AC!終わり!(平衡二分探索木がよく分からなくて、雑に二分探索で log を2個つけたら TLE したのはご愛嬌)
終わりに
証明や撃墜ケースなどが分かる方は教えてください
2024年に書いた問題の個人的振り返り
競プロでずっと作問していませんでしたが、ようやく問題を作り始めたので振り返りを書きます。
以下、想定解の解法についてはほぼ触れませんが、問題のネタバレを含みます(先に解いて欲しい気持ちはありますが、現在ほとんどジャッジがありません・・・ AOJ にすべての問題が移植されました!)
出題場所
JAG(FrontPage - ICPC OB/OG の会) にのみ問題を書きました。
- 国内予選(https://icpc2024.jag-icpc.org/icpcdomestic/contest/all_ja.html) : 2問(G, I)
- 夏合宿(https://jag-icpc.org/files/summer-camp-2024-day3-problemset.pdf): 5問 (C, D, E, J, K)
の全7問でした。
国内予選の問題
AOJ に移植されています
G 問題 数列の分割
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=3392
国内予選中盤以降の難易度の問題を作ろうと思って、まあ中盤くらいの難易度の問題が出来ました。
元々、各要素は正で、Lawler's K -Best Solutions のような top k 列挙アルゴリズムを出そうとしていましたが、非想定を落とせなかったので、問題設定も想定解法も変更されました(?)
I 問題 橋の建造計画 2
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=3394
国内予選の最終防衛問題を担当しました。かなり知識寄りですが、このタイプの知識は ICPC で出るのでセーフということで・・・
問題自体は何年か前に設定から解法を作っていました。国内予選という制約下での高難易度の問題がないということで「かなり知識寄りだけどそれでも良いなら」という感じで提案しました。 模擬国内中に通されるかはかなり怪しいと思っていましたが、某 guest チームは通すかもと思っていました(実際、解法自体は出ていて、実装時間の問題のようでした)。
ジャッジもついに公開されたので誰か解いてください。勉強にはなると思います。
夏合宿の問題
https://jag-icpc.org/files/summer-camp-2024-day3-problemset.pdf
2025年1月現在、どこにも移植されていません・・・
AOJ に移植されました!
以下、難易度順に書きます
Problem D: Paper Cut Game
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=3640
簡単枠を作ろうと思って、簡単ゲーム問題を作りました。実際、セット内で1番目か2番目に簡単だったようです。
高速に Grundy 数が計算出来て、紙の枚数を増やしても解けるんですが、「Grundy 数丸出しなのもなんだかな、簡単枠だし」と思って、1 枚の設定にしました。複数枚にした方がよかったのかな?
Grundy 数を計算する方針でなくても、実験してみればどっちの勝ちかの結果が見えて、住建にはこちら側の解法で解説されました。(Grundy数の計算はなんかごちゃごちゃしててややこしくしてね?と揶揄された、許すまじ)
Problem K: Equal or Not Equal
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=3647
これは大昔(5年前とか)に作問していた問題を引っ張りだしてきました。ちょうど真ん中あたりの難易度を想定して作っていました。
あまりクエリ問題は得意でないので、Yes, No, どっちも可能性ありうる っていう変わり種のクエリにすることで問題の新規性を主張・・・
現代だったらまあそこそこ解かれるだろうという想定での出題でしたが、WA, TLE が出て苦労していそうなチームもあり、予想よりも大変だったのかな、という印象でした。
Problem C: Commutativity
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=3639
このあたりから結構難しいです。実際、この問題が最後の崖になっていて、優勝を決める問題になっていました。2023年の夏合宿でも優勝を決める難易度の2乗制約数え上げを出したので、2年連続でおんなじ雰囲気の問題を出してしまったかも (2023夏合宿 Problem D: Many-hued Tree https://www.acmicpc.net/problem/30369) 。
問題自体は、順列のバージョンが線形時間想定解で 5 年前に pachicobue から提案されて yukicoder で tester して塩漬けしていました。 当時から一般の数列で解けるのかな?という話が出ていたんですが、夏合宿に出す前に真面目に考えて 2 乗で解けたのでパワーアップして出題。
考察自体は割と直線的ではありますが、乗り越えなければならない考察は多めで、結論として2乗で解けるのが面白いな~と思っています。 (JAGの内部コンテストで tester の hos さんに爆速で解かれて驚きましたが、流石にそこそこ難しいよなと思っていました。それは正しかったようです)
Problem E: Ball Passing
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=3641
みんな大好きパズル構築問題。シンプルな問題設定ですが、かなり難しいです。 トランプのゲームでこういうのがあったというのを思い出し、問題設定を考えて、解けたので出したというパターンです。
可能かどうか考える時点で難しい上に、それが分かって解けた!と思うと回数制限が本質的に難しいことに気付く、という形になっています。 実装も頭が混乱するタイプの問題なので、それも難易度を上昇させている要素だと思います。
コンテスト前日に、正当性の保証が出来ない乱択解法が見つかって対策を考えましたが、対策が出来そうもない感じ(おそらく正当性が証明できるのでは?)となったので、そのまま出しました。この解法だとかなり実装が軽くなるので色々怖かったです。
たくさん解かれることはないがどこかのチームが通してもおかしくないかなと思っていました。実際コンテストルームを巡回している際にこの問題に取り組んでいる人をそこそこ観測したので、頑張って!と思っていました。
競プロしていなくても分かる問題設定で、考察は面白いと思うので、ぜひ考えたり他の人に出題したりしてみてください。
Problem J: Draw the Tree
https://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=3646
最終防衛問題。すごく難しいです。 問題募集締切の1週間前に、問題が足りない(特に高難易度枠)という状況で、問題設定から考えました。
最初は可能性判定だけでしたが、それはわりかしすぐ解けてしまったので、幅を最適化させよう!という方向になりました。
まあ大体こんな感じで解けるし、詳細を詰めるのはしんどいけど頑張れば出来ます、と原案置き場に書いていましたが、もちろん頑張って詰めないと出題できません。 その結果、頭が壊れそうになりながら色々整理する羽目になりましたが、なんとか詳細を詰め切れたのでセーフ。
え、これ想定解とか誰が書くの?となりましたが、自分で書くしかありません。面倒なコーナーケースもちゃんと存在するので、ちゃんと対策しましょう。はい・・・。 テストケースも孤独に用意していたのですが、色々困った挙句、「制約小さくしても実装ほぼ変わらんし」ということで、制約も限界まで上げてみました(こういう高速化もあるよねと感じてもらうために・・・)。
一生懸命頑張って想定解とテストケースを作って tester を募集してみたものの、tester に名乗り出る人は一向に現れませんでした。 非常に困り果てたので、pachicobue をとっつかまえて tester をお願いしました(通すまで幽閉しました)。 一応解法の雰囲気は知っている状態でしたが、1日弱かかってました。このケース本当に想定解あってる?と言われて、ちゃんと図示して指摘する、などのやり取りが楽しい一日でした。
もちろん、コンテストで最難枠として出題しましたが、コンテストで誰か解いてくれないかな~とワクワクしていました。実際コンテストルームを巡回している際にこの問題に取り組んでいる人をチラホラ観測したので、(ものすごく)頑張って!と思っていました。(終了後、コンテスタントから、無理でしょ(意訳)というご指摘を受けました、涙)
頑張れば解けなくはないという感じなので、もしかしたら言われているよりも簡単かもしれません。ジャッジがどこかに生えたら解いてみてね。
おまけ(原案爆破)
ICPC yokohama regional で原案が1問爆破されました。
実は、Fと全く同じ問題を夏合宿で提案して棄却されていました……(問題の図を見てマジでビックリ)
— ホハム (@soiya_ksk) 2024年12月22日

この原案に対して、やや易という難易度評価をしていたのはご愛嬌、ということで・・・(実装してないからね!)
おわりに
2023 年は夏合宿の2問、2024年は模擬国内・夏合宿の7問ということで、1年で飛躍的進歩がみられました!
作問ネタが全然生えていないですが、2025年も頑張ろうと思います。ただ、いろんな人が JAG の問題を作ってくれそうな気がするので自分の出番はないかもしれません!
AGC044F Name-Preserving Clubs を解いた
AGC044F Name-Preserving Clubs を解いたのですが、かなり不思議な問題・解法だったので、解いたときの思考過程をメモしておきます(証明ではありません) atcoder.jp
問題概要
整数 $1, \ldots , N $ に対して、集合の多重集合 $S$ を構成したとき、以下を満たすものを良い構成とする - 任意の順列 $p$ について、$S$ 内の全ての要素を $i \rightarrow p(i)$ と変換した $S'$ が与えられた時に、 $p$ が特定できる
例えば、 $S = \{ \{1,2\}, \{2\} \}$ という構成に対して, $p = (2,1)$ とすると $S' = \{\{1,2\}, \{1\}\} $ となるが、$S'$ が与えられると $p$ が特定できる
これを満たすような $S$ の中で追加した集合の数が最小となる $S$ のパターンは何通りあるか。ただし、順列による変換を行って一致するような $S$ は同一視し、パターンが 1000 を超える場合は -1 を出力せよ。
実験
$N$ が大きい場合、パターン数は 1000 を超えそうなので、$N>=100$ なら $-1$ を返して、そうでないなら assert で落としてみる
そっか・・・
追加する集合の数の最小値 $K$ の計算
恐らく$2$ 冪が絡むだろうことは分かり、$\log_2(N)$ くらいは必要そうであることは分かる。順列がどうのこうのが良く分からないのでとりあえず実験・・・。
- 実験結果: 追加する集合の数を $K=1,2,\ldots$ としたときに構成可能な $N$ の最大値 $F(K)$ は、$2, 3, 6, 13, 29, \ldots$ となる
やはり $F(K) = 2^{K} - c(K)$ の形が最大値になりそう。
良くある話だが、$K$ 個の「区別がついている」集合がある場合、各集合に含まれているか否かで、$2^{K}$ 個の要素を分類可能である。 $i$ 番目の集合に含まれている場合 $i$ bit 目を立てることで、$0, \ldots, 2^{K}-1$ に対応する。
そこで逆に考えると、$0, \ldots, 2^{K}-1$ から何個かの数字を取り除いた場合に、$K$ bit が区別できれば、順列で変換されたとしても $2^{K} - $ (取り除いた個数)を区別することが出来る。
そのため、$c(K)$は $K$ 個のものを区別するために必要な最小の集合の個数と言い換えることができ、これは元の問題のより小さい問題になっている。よって、$c(K) =$($F(x) \ge K$ となる最小の $x$) になる。
パターン数 $P(N)$の計算
まず、十分大きいところでは、$N = F(K)$ と表現されるような $N$ だけ考えればよいと雰囲気で分かる($N = F(K)$ を達成する構成から集合を消していくことを考えると、候補は $N$ に比例して大きくなりそうで簡単に $1000$ を超えるように見える)。
$N = F(K)$ と表現される $N$ については、最小値の計算と同様の議論をすると、 $P(N) = P(K)$ となると考えられる ($N$ 個を $K$ 個の集合で区別する表現は、$K$ bit を $c(K)$ 個の整数で区別する表現に言い換えられるという議論はパターン数でも同じはず)。
以上より、$F(K)$ は大体 $2$ の指数乗になっているため、 $1 \le N \le 61$ までを前計算してテーブルで埋め込んで、$N \ge 62$ 以上は $N = F(K)$ を満たす場合のみ、 $P(N) = P(K)$ そうでない場合は、$1000$ を超えると判定すればよい。
コーナーケース
・・・で終わればよいのだが、これまでの議論には大きな落とし穴がある。
実は $N = 4, 7$ の場合、同じ集合を $2$ つ追加するような特殊な集合の構成が存在する($N=4$ のサンプルがあって優しいね)。 $N$ が小さいため、情報量的に損していそうな同じ集合の追加でも区別が出来てしまう。
これまでしてきた、$N = F(K)$ での言い換えの議論では、「異なる集合」によって区別することを勝手に仮定してしまっていた。 そのため、同じ集合を $2$ つ追加するような特殊な構成に対しては、「$K$ bit を $c(K)$ 個の整数で区別する」 側の表現に言い換えることができない。 例えば、$N =124 = F(7)$ の場合がコーナーケースで、 $P(7) = 336$ であるが、$2$ 個同じ集合を $2$ つ追加する構成が存在するため、$P(124) = 334$ となる。この場合分けに気を付けると AC できた。
Seimei Handan 999.0 (JAG 2022年模擬地区予選F) を決定的に解く
この記事は帰ってきた AOJ-ICPC Advent Calendar 2022 - Adventarの20日目の記事です.
問題概要
各要素が $1$ 以上 $L$ 以下の整数列 $A = (a_1,\dots,a_N),B = (b_1,\dots,b_M)$ が与えられる.
整数に対して定義される全単射の写像 $f : [1,L] \rightarrow [1,L]$ の内,$(f(a_1),\dots,f(a_n))$ の部分連続列として $B = (b_1,\dots,b_M)$ を含むようなものは何通りあるか,modulo 998,244,353 で答えよ.
制約
- $1\leq N \leq 300,000$
- $1 \leq M \leq N$
- $1 \leq L \leq 300,000$
(以下のリンク先に正式な問題文があります)
2022/Practice/模擬地区予選/問題文とデータセット - ICPC OB/OG の会
はじめに(ここからネタバレあり)
この問題は,ハッシュを利用して解くこともできます(解説の想定解 1 ).
以下では,個人的興味から文字列アルゴリズムを駆使して決定的に解く方法を書きます(つまり,解説の想定解 2 について詳しく書きます).
問題の言い換え
$i$ 番目の index から始まる連続部分列$(f(a_{i}),\dots , f( a_{ i + M - 1 } ))$ が $B$ に一致することを考えます.このとき,そのような $f$ が存在する場合,$(a_{i},\dots , a_{ i + M - 1 } )$ に含まれる数字の変換先は一意に特定され,それ以外の数字に関してはどのような割り当ても許されることになります.よって,$(f(a_{i}),\dots , f( a_{ i + M - 1 } ))$ が $B$ に一致する $f$ が存在するならば,$(a_{i},\dots,a_{ i + M - 1 })$ に含まれる数字の種類を$L'$ として $(L-L')!$ 通りの $f$ が条件を満たします.
異なる $i, j$ について,$(a_{i},\dots,a_{ i + M - 1 })$ と $(a_{j},\dots,a_{ j + M - 1 })$ がそれぞれ条件を満たす$f$ を持つ場合を考えます.このとき,条件を満たす$f$ の集合は、$(a_{i},\dots,a_{ i + M - 1 }) = (a_{j},\dots,a_{ j + M - 1 })$ ならば、明らかに両者で一致します.逆に $(a_{i},\dots,a_{ i + M - 1 }) \neq (a_{j},\dots,a_{ j + M - 1 })$ ならば,disjoint であることが分かります.これらは$A$の部分連続列同士が一致するかの判定なので,suffix array, LCP array を用いれば決定的な判定が可能です.*1
以上より,「$(f(a_{i}),\dots , f( a_{ i + M - 1 } ))$ が $B$ に一致する $f$ が存在する」ような $i$ を全て求めた後に,部分列 $(a_{i},\dots , a_{ i + M - 1 } )$ の種類が何種類あるかを求められれば $f$ の総数が分かります.部分列 $(a_{i},\dots , a_{ i + M - 1 } )$ の種類が何種類あるかは、$A$の部分連続列同士が一致判定と同様に,suffix array, LCP array を用いて計算できます.こちらに関しては suffix array, LCP array を使う例題としてよく出てくるものなので、割愛させていただきます.
背景知識:parameterized pattern matching
上記の議論から、「$(f(a_{i}),\dots , f( a_{ i + M - 1 } ))$ が $B$ に一致する $f$ が存在する」ような $i$ が全て求められればよいことが分かりました.
この条件には,parameterized pattern matching [1] という概念が背景知識としてあります.ざっくりとした定義は以下の通りです.
定義: (parameterized pattern matching)
parameterized string (p-string) は constant と parameter の大きく分けて2種類の(広義の)文字からなる
- constant: いわゆる通常の文字に対応する. *2
- parameter: 変数に対応する(後述する p-match を参照).
2つの p-string $S, T$ が parameterized match (p-match) するとは以下の状況を指す.
- parameter の(有限)集合を $\Pi$ として、ある $\Pi \rightarrow \Pi$ となる全単射$f$ が存在し,$S$ に含まれる parameters を $f$ で変換したときに $T$ と一致する.
例: p-match
constants: $\text{A},\text{B},\text{C}$, parameters: {$x,y,z$} とするとき,以下のようになります.
- $\text{A}x\text{B}yx$ と $\text{A}z\text{B}yz$ は p-match する ($f(x)=z, f(y)=y,f(z)=x$)
- $\text{A}x\text{B}yx$ と $\text{A}z\text{B}zz$ は p-match しない ($f(x)= f(y)=z$ は許されない)
- $\text{A}x\text{B}yx$ と $\text{A}z\text{C}yz$ は p-match しない (3文字目が $\text{B} \neq \text{C}$)
parameterized pattern matching という概念を用いると、今回の問題は「parameters のみからなる p-string $A,B$に対して、$B$ に p-match する $A$ の連続部分列 (p-substring) を全て求めよ」という問題になります.
prev encoding
p-string に対して、以下の変換 prev encoding を考えます(今回の問題では parameters のみを考えればよいですが,一応 constants も考えることにします).
定義: (prev encoding)
p-string $S$に対して、$S$ と同じ長さの列 $\text{prev}(S)$を以下のように定義する.
- $i$番目の文字 $x$ が constant の場合: $\text{prev}(S)[i] = x$
- $i$番目の文字 $x$ が parameter の場合:
- $x$ が p-string 内で先頭から見て初めて現れた場合: $\text{prev}(S)[i] = 0$
- そうでない場合: $\text{prev}(S)[i] = i - (i$番目より前で直近に出現した$x$の位置)
例えば, p-string $\text{A}x\text{B}yxy$ に対して,$\text{prev}(\text{A}x\text{B}yxy) = \text{A}0\text{B}032$ となります.
この時,prev encoding は以下の重要な性質を満たします.
性質: p-string $S, T$ が p-match $\Leftrightarrow$ $\text{prev}(S) = \text{prev}(T)$
よって,p-string の p-match が prev encoding した文字列の一致として判定可能になります.
Morris-Pratt algorithm を p-string に適用する
文字列検索の有名なアルゴリズムとして Morris-Pratt algorithm (以下,MP 法) があります.
MP 法は長さ $n$ の文字列 $S$ が与えられた際に,$0\leq i < n$ について $S[0:i]$ の接頭辞と接尾辞が最大何文字一致しているか(ただし,$S[0:i]$ そのものは除く)の配列を計算するアルゴリズムです.この配列を用いて、文字列検索を行うことができます(MP法の詳細の説明は割愛します.例えば,文字列の頭良い感じの線形アルゴリズムたち - あなたは嘘つきですかと聞かれたら「YES」と答えるブログ や https://hcpc-hokudai.github.io/archive/string_algorithms_001.pdf などで説明されています).
実は通常の文字列に対する MP 法にほんの少しの修正を加えるだけで,p-string に対する文字列検索を行うことができます.以下では,問題の設定と同様に parameter のみからなる p-string について扱います(constant なものが混じっている場合でもほとんど同じようなコードでできます).
通常の MP 法 (入力の文字列 $s$, 求める配列は table に格納される)
class MP
{
public:
string pattern;
int plen;
vector<int> table;
MP(const string& s) : pattern(s), plen((int)pattern.size()), table(plen + 1){
table[0] = -1;
int j = -1;
for(int i = 0; i < plen; ++i){
while(j >= 0 && pattern[i] != pattern[j]){
j = table[j];
}
table[i+1] = ++j;
}
}
void search(const string& text, vector<int>& res){
int head = 0, j = 0, tlen = (int)text.size();
while(head + j < tlen){
if(pattern[j] == text[head + j]) {
if(++j == plen){
res.push_back(head);
head = head + j - table[j];
j = table[j];
}
}else{
head = head + j - table[j];
if(j) j = table[j];
}
}
}
};
p-string の MP 法 (ただし,入力 $s$ は p-string を prev encoding したもの)
class MP
{
public:
vector<int> pattern;
int plen;
vector<int>table;
MP(const vector<int>& s):pattern(s),plen((int)pattern.size()),table(plen+1){
table[0] = -1;
int j = -1;
for(int i=0;i<plen;i++){
while(j>=0 && pattern[j] != (pattern[i]<=j ? pattern[i] : 0)){
j = table[j];
}
table[i+1] = ++j;
}
}
void search(const vector<int>& text,vector<int> &res){
int head = 0, j = 0,tlen = (int)text.size();
while(head + j < tlen){
if(pattern[j] == (text[head+j]<=j ? text[head+j] : 0)){
if(++j == plen){
res.push_back(head);
head = head + j - table[j];
j = table[j];
}
}else{
head = head + j - table[j];
if(j) j = table[j];
}
}
}
};コードを見比べてもらえれば分かりますが,文字の不一致判定を
pattern[j] != (hoge[*]<=j ? hoge[*] : 0)
に修正しているだけです.
逆になぜ文字列の比較に修正が必要かというと,prev encoding した文字列について部分文字列の比較を考える際に,
$S[i:i+x]$ と $S[j,j+x]$ が p-match する $\not\Leftrightarrow$ $\text{prev}(S)[i:i+x] = \text{prev}(S)[j:j+x]$
であるためです.
例えば,$S = xyzzxy$ について,$\text{prev}(S) = 000144$ となり,$\text{prev}(S)[0:3] = 000 \neq 144 = \text{prev}(S)[3:6]$ ですが,$S[0:3] = xyz$ と $S[3:6] = zxy$ は p-match します.
そこで,prev encoding を見て部分文字列の一致を判定する際には,各文字の prev について参照している index が現在の部分文字列の先頭より前かどうかを確認した上で判定してやればよいです.これが MP 法を修正した箇所となります.

逆に,文字の一致判定以外は,通常の文字列に対する MP 法の正当性の議論と同様の議論をすることで、p-string に対する MP 法も問題なく動くことが分かります.
全実装
以上より,この問題は解くことができます.実装例は以下の通りです(suffix array と LCP array でやるところはサボって Rolling Hash で書きました)
#include<bits/stdc++.h>
using namespace std;
#define rep(i,n) for(int i=0;i<(int)(n);i++)
typedef long long ll;
class MP
{
public:
vector<int> pattern;
int plen;
vector<int>table;
MP(const vector<int>& s):pattern(s),plen((int)pattern.size()),table(plen+1){
table[0] = -1;
int j = -1;
for(int i=0;i<plen;i++){
while(j>=0 && pattern[j] != (pattern[i]<=j ? pattern[i] : 0)){
j = table[j];
}
table[i+1] = ++j;
}
}
void search(const vector<int>& text,vector<int> &res){
int head = 0, j = 0,tlen = (int)text.size();
while(head + j < tlen){
if(pattern[j] == (text[head+j]<=j ? text[head+j] : 0)){
if(++j == plen){
res.push_back(head);
head = head + j - table[j];
j = table[j];
}
}else{
head = head + j - table[j];
if(j) j = table[j];
}
}
}
};
struct RH{
static int mod[2], mul[2];
static vector<int> pm[2];
int sz;
vector<vector<int> > hs;
RH(const vector<int>& s): sz((int)s.size()),hs(2,vector<int>(sz+1,0)){
rep(i,2){
if(pm[i].empty())pm[i].push_back(1);
rep(j,sz){
hs[i][j+1] = ((ll)hs[i][j] * mul[i] + s[j])% mod[i];
}
}
}
pair<int,int> hash(int l,int r){
if(l>=r)return {0,0};
int res[2];
rep(i,2){
while(pm[i].size() <= r){
pm[i].push_back((ll)pm[i].back() * mul[i] % mod[i]);
}
res[i] = (hs[i][r] - (ll)hs[i][l] * pm[i][r-l])%mod[i] + mod[i];
res[i] = (res[i] >= mod[i]) ? (res[i]-mod[i]) : res[i];
}
return {res[0],res[1]};
}
};
vector<int> RH::pm[2];
int RH::mod[2] = {1000000007,1000000009}, RH::mul[2] = {10009,10007};
ll MOD = 998244353;
ll fac[300001];
vector<int> prev_encoding(vector<int>&a){
map<int,int> last_id;
int n = a.size();
vector<int> prev(n);
rep(i,n){
if(last_id.find(a[i])==last_id.end()){
prev[i] = 0;
}else{
prev[i] = i - last_id[a[i]];
}
last_id[a[i]] = i;
}
return prev;
}
int main(){
fac[0] = 1;
for(int i=1;i<=300000;i++){
fac[i] = fac[i-1] * i % MOD;
}
int n,m,L;
cin >> n >> m >> L;
vector<int> a(n);
vector<int> b(m);
rep(i,n) cin >> a[i];
rep(i,m) cin >> b[i];
vector<int> A = prev_encoding(a);
vector<int> B = prev_encoding(b);
int C = 0;
rep(i,m)C += (B[i]==0);
MP mp(B);
vector<int> res;
mp.search(A,res);
set<pair<int,int> > st;
RH rh(a);
for(auto x:res){
st.insert(rh.hash(x,x+m));
}
cout << fac[L-C] * st.size() % MOD << endl;
return 0;
}
参考文献
1. B. S. Baker, "A Theory of Parameterized Pattern Matching: Algorithms and Applications," In Proceedings of the Twenty-Fifth Annual ACM Symposium on Theory of Computing, pp. 71--80, 1993.
感想
実は,私の修士時代の最初の研究テーマが parameterized pattern matching に関連する内容でした.Twitter で何度か parameterized pattern matching 出すか~(笑) みたいなことを言っていたので,そのものが出てきてコンテスト中本当にビックリしました.
今回の問題では p-string の prev encoding さえ分かれば解ける問題となっていましたが,この記事では Morris-Pratt algorithm を修正して適用したように,p-string に対して普通の文字列と同様に様々な計算ができることが知られています(例えば,pSA, pLCP, pST, pBWT ... などいろいろとできます.簡潔データ構造も提案されています).最近でも論文が出ている認識なので,興味のある方は深堀りしてみると面白いと思います.*3
AtCoder でレッドコーダーになりました
AtCoder にレートがつき始めた AGC001 で初めてコンテストに参加して、苦節6年半、ようやくレッドコーダーになれました pic.twitter.com/oidsYpuzr7
— ホハム (@soiya_ksk) December 4, 2022
タイトルの通り、AtCoder でレッドコーダーになりました。
折角なので、ブログ記事を書くことにしました。
競技プログラミングとの出会い
大学1年の時に、AOJ の問題を1週間に1問解くと単位がもらえるという講義があり、それで初めて競プロを知りました。ただ、その頃は単位を取るためだけにやっていたので、1週間に1問解くだけでした。
2016年7月16日 コンテストに参加し始める
コンテストに参加し始めたのは、
2016年7月16日 AtCoder Grand Contest 001
が初めてでした(ツイートを調べると、期末試験直前の現実逃避として始めていそうでした)。
この時点(大学3年)でのプログラミング経験は、大学の教養の講義で JavaScript, Ruby を触ったことがある程度、学科の講義で C 言語を触ったことがある程度だったと思います。
2017年4月15日 黄色に到達
黄色くなった嬉しぃ〜〜〜〜 pic.twitter.com/NDR9p7DGIc
— ホハム (@soiya_ksk) April 15, 2017
このころ(大学4年)は学科の同期が何人か一緒に競プロをやっていて、
一緒に ICPC 2017 に出ることになる polyomino, hyksm
コドフォの gym をやりまくることになる kopricky, pachicobue
などと一緒に AOJ-ICPC の話を学科控室でワイワイしていました。
黄色になった当時は DFS すら書けなかった記憶があります。今では DFS が書けないのに黄色になれるということはなさそうなので時代を感じますね。
2019年8月24日 橙色に到達
ようやくオレンジになった!嬉しい! pic.twitter.com/uxxlq7ciBn
— ホハム (@soiya_ksk) August 24, 2019
修士2年の時に、橙色に到達しました。このころ、(修論からの逃避行為の一環で?)AtCoder Problems で黄色~赤色埋めをし始めました。修論発表当日も緊張を紛らわすために、行きの電車でAGC001 D - Stamp Rally を埋めたりしていました。kenkoooo さんには感謝の念しかありません。
ICPC 2018 では、ats 君、polyomino と一緒に地区予選まで行きました。ICPC は 2017, 2018 の2回しか参加できませんでしたが、本当に楽しかったなぁと思います。
RPS精進、赤色チャレンジに失敗し続ける
社会人になってから、何故か gym チームバチャ、 AGC 埋めが加速します。
kopricky, pachicobue と Bue_World というチームで gym のチームコンを 50 バチャくらい走りました。
ついでにRPS 精進も行い、残り問題数も管理していました(https://kenkoooo.com/atcoder/#/contest/show/91528c6f-c0dd-4975-b943-cc0992d533a3)
最高時は Rated Point Sum 2位、Rated の問題は残り20問切るくらいまで行っていました(現在は Rated Point Sum は3位、解いていない問題は一杯)。
AGC埋めについては、最後のほうは銀パフォ上位、金パフォ、難易度すらついていない、みたいなゾーンになっていて、一週間くらい空いている時間にずっと考えてようやく1問解けるかみたいなことになっていました。
レートに関しては橙になってからも比較的順調に伸び続け、
2021年2月13日には 2748 まで行き、レッドコーダーチャレンジゾーン(ARC 1回でレッドになりうるゾーン)に初めて突入しました。
2021年5月10日には 2797 になり、その後1年以上赤未達成内 highest レート1位を保持し続けることになります。
2021年11月28日の 2787 を最後に泥沼が始まり、2022年6月19日には 2568 まで落ちました。このあたりでもう結構赤は無理かなぁという感じになっていて、同時にこの時期に転職もして競プロ精進も終了したので、まあここからは惰性で続けるだけだな・・・という気持ちでした。
2022年12月5日 赤色に到達
それからコンテストに出ることしか競プロをしていませんでしたが、問題との相性が良かったのか赤パフォを連発、それまで1回しか取ったことのなかった銀パフォも2回取って、泥沼が始まった2021年11月28日での 2787 まで戻した状態で AGC 059 を迎えました。
AGC059では A, B, C を通したタイミングで9位で、赤色を確信しました。コンテスト中でしたが、流石に目がウルっときました。(その後 E 問題に飛びついて無事WAを連発しました)
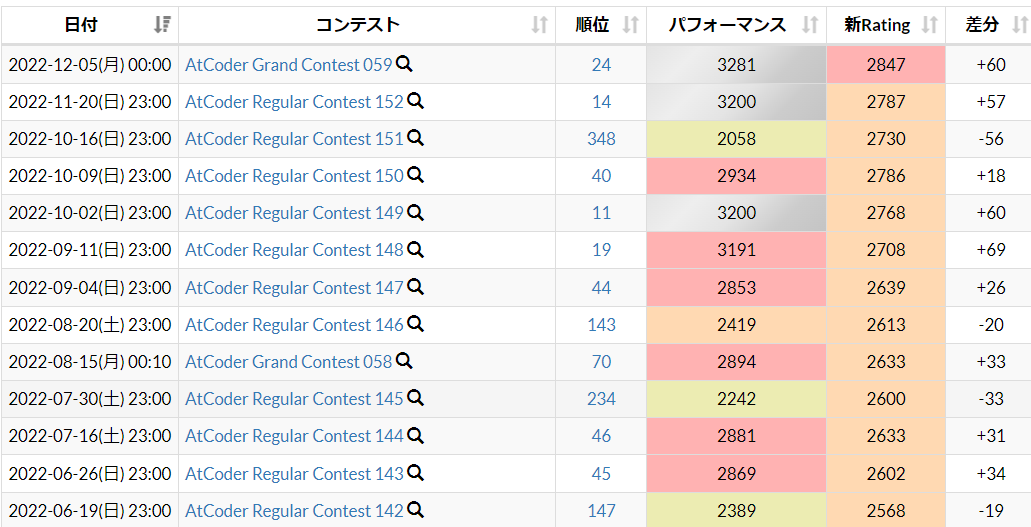
17 回目のレッドコーダーチャレンジでした。
AGC 埋めをしまくった結果、AGC で3200↑ パフォを出して赤になれて、精進が報われた気がしました。
統計情報
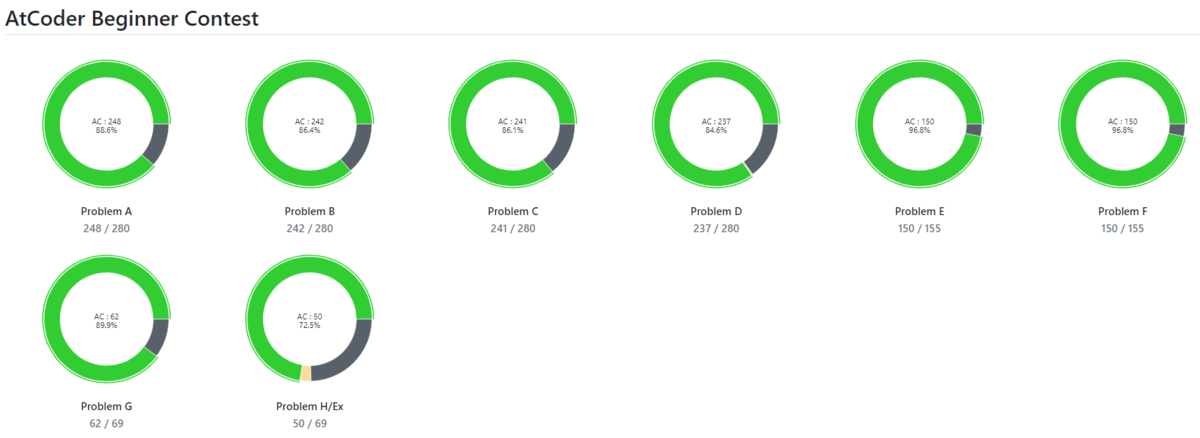
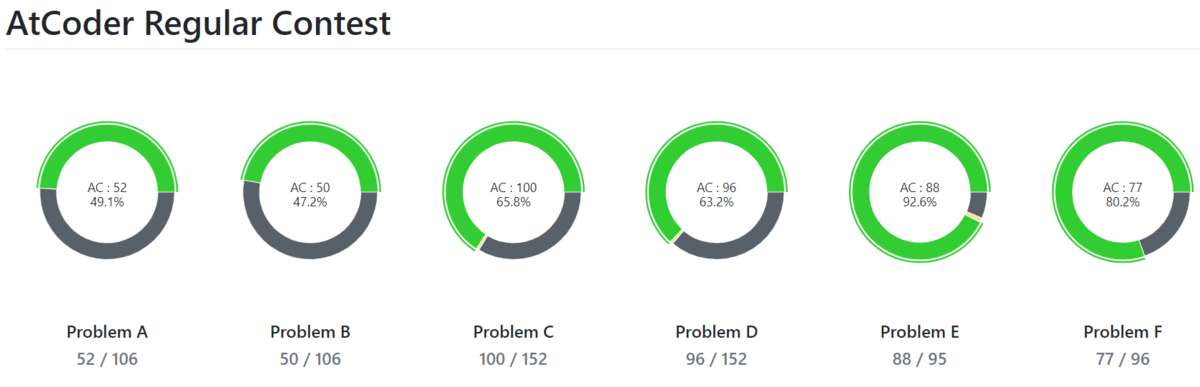
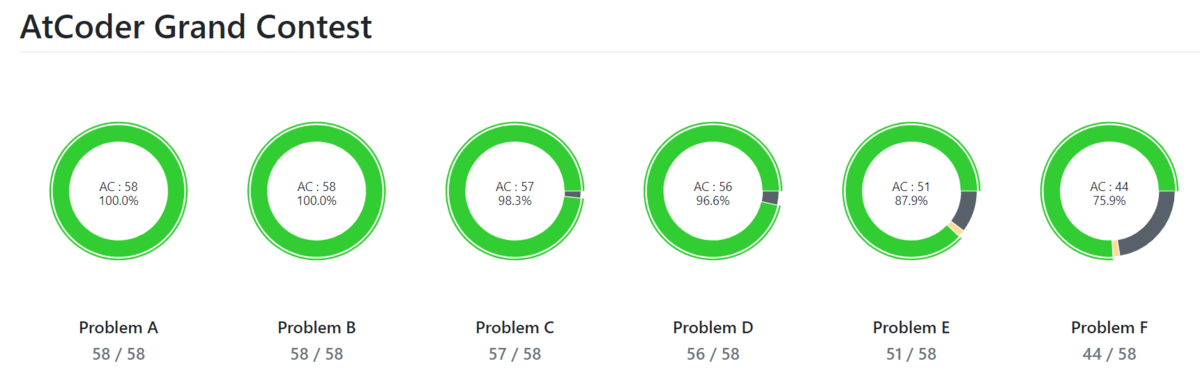
旧ABC. ARC はほとんど埋めていないです。
AGC埋め頑張ったなぁ・・・
個人的な感想一覧
- AGC は特殊な問題が多い割に、AGC の頻度は高くないので、 AGC 埋めはレート向上には多分そんなに活きない
- 早解きに苦手意識を持っていたので、早解き失敗で冷え確定はツラかった
- 多分コドフォバチャを大量にやるとかして、早解き力を上げるのが一番レートに良い
- 競プロはメンタルゲー
- AGC埋めは楽しかった
- チームバチャも楽しかった
- 自分の脳力的にはここがかなり限界値
終わりに
AtCoder でレッドコーダーになることは、自分には厳しいかもしれないけれどいつか達成できたらいいなという目標だったので、本当に嬉しいです。
競技プログラミングと出会って、人生は大きく変わった(歪んだ?)と思います。少なくとも、研究室、職業の選択には大きな影響が自分にはありました。
また、競技プログラミングを通じて知り合いが増えたり、新たな繋がりが得られたりしたのは良かったです。自分一人ではここまで続けていなかっただろうなと思います。
これ以上上を目指すのは自分には厳しいかなという気持ちだったりするので、これからはコンテストにだけ出るくらいで、のんびり競プロ界隈に居続けようかなと今は考えています。
おまけ
ここまで読んでいただいた方向けに、自分が AtCoder の RPS 精進をしているときに出会って面白かった、印象に強く残っている問題を4問ほど並べておきます。
ICPC2022 模擬国内予選参加記
概要
ICPC2022模擬国内予選 (2022/Practice/模擬国内予選/案内 - ICPC OB/OG の会) に参加しました。
結果は ABCDEFG の7完で2位でした。
模擬国内2位!ヘヘッ pic.twitter.com/ZwGQ2JWzuj
— ホハム (@soiya_ksk) 2022年6月25日
チーム名は Bue World でチームメンバーは kopricky, mtsd, pachicobue でした。
もちろん今年の ICPC 参加資格はありません。
経緯
模擬国内予選が開催されることを 2 人に伝えましたが、kopricky の生存確認が取れることは稀で、このままだとパチコと 2 人参加だな~と思っていました。
6/18(土)午後 3 時 48 分 kopricky :「ところで模擬国内出るぶえ!(たぶん)」
良かった~
6/25 当日
30分前に全員の起床を確認。コンテスト10分前にパチコと dicord で合流。
午後1時。コンテストが始まりました。
とりあえず自分が A を読み、パチコが B を読むことに。
(開始して数分経ったところで、koprickyも現れました。kopricky「よし!やるぞ!」)
A問題:連番
N 個の整数からなる列 A = (a1, a2, ..., aN) が与えられる.A を昇順に並べかえたとき,連続する整数が続く区間の長さの最大値を求めよ.
なるほどなるほど、流石に A は簡単だと、
int res = 0;
int tmp = 1;
for(int i=0;i<n-1;i++){
if(a[i]+1==a[i+1])tmp++;
else{
chmax(res,tmp);
tmp = 1;
}
}
chmax(res,tmp);
と書くも、サンプルが合わない。もうダメかもしれないなと思って問題文を読み返すと "A を昇順に並べかえたとき" と書いてあった。最初から sort しておいてくれよと思いながら直して、提出システムにまごつきながら AC (0:06:01)。
その間に、パチコが B を実装して、kopricky が C をやっていました。(BとCに関しては完全並列なため全く把握してません)
パチコが B 大変だなと言ってたような気がしますが、すぐに AC (0:12:49)。
その間に自分が D をやり始めていました。
D 問題:動く点 P と愉快な仲間たち Q, R
凸 N 角形上を 3 点が動く問題。3 <= N <= 2000。
どれかの点が隣の頂点に到着するごとに時間の区間を区切ることを考える。
D 問題の幾何だし、大体こういうのは各区間で下に凸!三分探索!そうじゃないと解けません!と言ってそのまま書き始める。
意外と実装は重くなく、適当に書いてみたらサンプルが合う。まあ投げてみるっしょで AC (0:23:21)。
そんなこんなしている間にこれどうやって提出するんだっけ?とか言っていた koprickyが C も AC (0:28:55)
E の問題文を見た瞬間にパチコ用の問題であることが分かったので、特に何も考えずにパチコに E 問題の全権を託す。そしたら爆速で AC (0:40:42)。流石パチコとしか言いようがなかった。
ここからは、
F 問題 : kopricky, mtsd
G 問題:pachicobue
という分担で進めることに。
F 問題 : N 階ダンジョンと K 人の勇者たち
この問題を読んですぐ、「最小流量制約+流量に対して線形にコストが上がっていく最小費用流」であることは分かった。
kopricky はフロー周りを詳しかったはずなので(色々実装してるし)、話し合いながら考察を進める。
流量の分だけ辺を追加して間に合う?とか言ってみるもまあ無理だよねという話に。
凸費用流は解けるって聞いたことあるなと思って、いろいろ調べてみるもあんまりよく分からず。kopricky に流石にその方向性はやばくね?と諭されたので、フローのお気持ちを考えることに。
まあよくわからんけど、最短路反復の際に見る辺って実は各辺について、現在の流量+1の辺と現在の流量の逆辺 だけでいいんじゃない?と試しに言ってみる。
ほんとぉ?と言われるも、まあこれじゃなかったらこの問題は解けねえと言ってみる。最小費用流ってどうやって更新するんだっけ、ポテンシャルとかなんかあったよねと、いろんな文献とライブラリを眺めながら苦しむことに。
まあ辺のコスト変える方針でいっちょ書いてみるか!と自分がコーディングへ。
最小流量制約ってどうやるのか忘れたな、まあ -INF みたいな辺で管理すりゃええか!-> 辺のコストガチャガチャ変えて壊れんのかな、まあ壊れん壊れん!
と雰囲気でライブラリを改造してみると、サンプルがある程度合って、ほんとぉ?と言いながら提出しようかなという気持ちに。
でもちょっと待てよ、これ答え long long のギリギリまで大きくなるけど -INF とかやって大丈夫なの? -> うーん、ダメそう... -> 実際にテストケースをダウンロードしてみて、流量制約について valid かの test を書いて自分の出力と比較すると、valid なものに対して -1 を返していて涙。
ええい! int128 で管理したれ! -> なんか出力が全部壊れました。涙。
ここら辺で険しいよ~と kopricky に助けを求めるも、あまり伝えても意味がなさそうだったので、ライブラリのどこでおかしくなっているかを確認しに行くとstd::numeric_limits<__int128_t>::max() とかがかなり怪しそうという気持ちに。
INF 周りをいじくりまくったらようやくそれっぽい出力になり、ええい提出してやれ!と提出すると AC (02:01:39)。1時間半かかりました。long long ギリギリを攻めるのやめてくれ~。
順位表を見るとこの時点で 3位 に!
ん?よく見ると F に1ペナ生えてる。kopricky、なんか提出ミスっちゃったかも。。。
kopricky 「あ、バレた?」(愚直を出力したら爆速で終わったらしいので提出したら出力が普通におかしくて WA を生やしていたらしいです)
そんなこんなで、パチコの G の様子を聞いてみると、最適値が合うところまで来たけど復元がまだ上手く行ってないと伝えられる。
じゃあ H 読んでおくかと H にトライ。
H問題 : パレード
問題は、単純連結無向グラフが与えられ、
条件1. 各辺については2回まで通ってよいけど、連続では通ってはダメ
条件2. 各辺について1回以上通るような一筆書き
の2つの条件を満たす経路を求めるような問題。
とりあえず自明にダメなケースとして、次数1 の頂点が 3つ以上あるケースはダメとわかる。
0 or 2 の場合を考えればよい。(これ今見ると嘘で、何故か偶数個しかないと勘違いしてるね)
多分これは必ず経路が作れるんだろうなという競プロ勘が働き、どうやって構築するかなという気持ちになる。
とりあえず次数 1 の頂点が 2 個 s, t の場合を考えてみると、とりあえず適当に 1 つ s-t パスを取りのぞいてみて、すべての辺を倍化してやればオイラー路の感じで出来そう。
あとはいい感じにガチャガチャやるのかな~?
と考えていたところで、パチコから G の HELP 要請が。
どうやら、G問題の大体はできているが、経路を作るところで嘘が見つかりハマっていたらしい。
頂点1,2,...,n が順に並んでいて、各頂点 x について x より番号が小さい頂点に伸びる辺の数と x より番号が大きい頂点に伸びる辺の数(合わせて辺の数は高々2)が与えられるので、オイラー路を作成してください
という問題が解ければよいというところまで来ているとのこと。
頂点番号が小さい方から順に処理して貪欲に辺を加えていけばよいと思うんだけど、上手くいかないケースがある。という話だった。
よく聞いてみると、スタートとゴールを途中でくっつけてしまっている場合があったらしく、じゃあスタートとゴールをくっつく場合はそれを回避するように貪欲を書けばいいんじゃないと言ってみる。なんかそれで上手く行きそうという話に。
もう残り時間もわずかで、なんか上手くいかない -> いやバグってた をしていて、冷や冷やしながら応援すると AC! (02:53:20)
ここから H を悪あがきで考えてみると、
今見ている walk が s-u-v-t となっていて、walk に含まれる辺を含まないような u-v walk があったとすると、
s-(今のwalkに含まれない u- v) - (今のwalk の v-u) - (今のwalkに含まれない u- v) - t
の順に繋ぎなおせばうまくいきそうという気になってくる。
O(M^2)だけどこれを実装したれ!と実装し始めるももちろん間に合わずに終了。
Hをヤケクソで実装している間、後の2人は阪神-中日戦を見ていました(阪神10-0中日)。
終わった後に20分追加で書いてみて、テストケース公開後に回してみるもどこかで無限ループが発生していましたとさ。おしまい。
まとめ
強豪チームはフルで参加していないチームも多そうでしたが、模擬国内で 2 位をとることができて嬉しかったです!
ICPCの参加資格を数年前に失っているのにチームバチャを謎にたくさんやっていた甲斐がありました!
各人の得意分野はかなりお互いに把握していて、しかも得意分野(やる分野)はほとんどかぶっていない
kopricky : データ構造、セグ木系、知識
pachicobue : 数学系、PEみたいのとか
mtsd : その他(二人が苦手な分野、パズル、ゲーム系、実装するだけをやらされる)
という感じなので、チームコンはやりたい問題だけできて楽しいです(幾何だけ醜い押し付け合いが始まります)。
いつまで OB が模擬国内に出ているんだという感じですが・・・
いつまで出てるんだと思われても出る強い意志、それが一番大事
— ホハム (@soiya_ksk) 2022年6月25日
AtCoder Heuristic Contest 011 参加記 (6位)
AtCoder Heuristic Contest 011 に参加しました。
結果は 6 位でした。
解法を大雑把に言うと、「盤面と操作列を同時にビームサーチで探索する」です。
せっかくなので、時系列順にやったことをまとめてみます(問題概要は省略します)。
第一実装:最終盤面、操作列の順に作って大きさ  の木を作る
の木を作る
最終的に上位とやり合うためには、大きさ の木(完全解と呼ぶ)を作らなければならないと推測されたので、まず完全解を作ることから考えました。そこで、
完全解となる有効な最終盤面を1つ構築 -> その盤面になるような操作列を構築
の順で構築して完全解を作ることを第一実装の目標としました。
完全解となる有効な最終盤面を作る
Web 版のツールを使って手作業で何かヒントを得ようとしましたがサッパリ分からなかったので、乱拓 DFS で盤面を作ることをまず考えました。
ここで、「完成図が1つの木になっている」条件と「スライドパズルで遷移可能である」条件の2つを考えなければいけませんが、先に「スライドパズルで遷移可能である」条件を考えておきます。
- スライドパズルで遷移可能である条件
高校数学(?) によると、各タイルに番号を振って 1 対 1 の対応付けを行った後は、「置換のパリティと空きマスの移動距離のパリティが一致している」ことが遷移可能の条件です。
ここで、仮に適当に盤面を作ってタイルに番号をテキトーに振った時に、上記のパリティ条件が成立しなかったとします。
このとき、タイルの種類は 15 種類であることから同じ種類のタイルが必ず 2 つ以上あるため、2 枚の同じ種類のタイルの番号を入れ替えることで、盤面の図はそのままでパリティ条件を満たすことが出来ます。
よって、最終状態の図を 1 つ固定した場合、その図を作るような操作列は必ず作れることが分かります。操作列のことは考えず、盤面の木をどうやって作るかを考えれば良いことが分かりました。
- 何枚かタイルを置いた時点での完成図が 1 つの木になるための必要条件
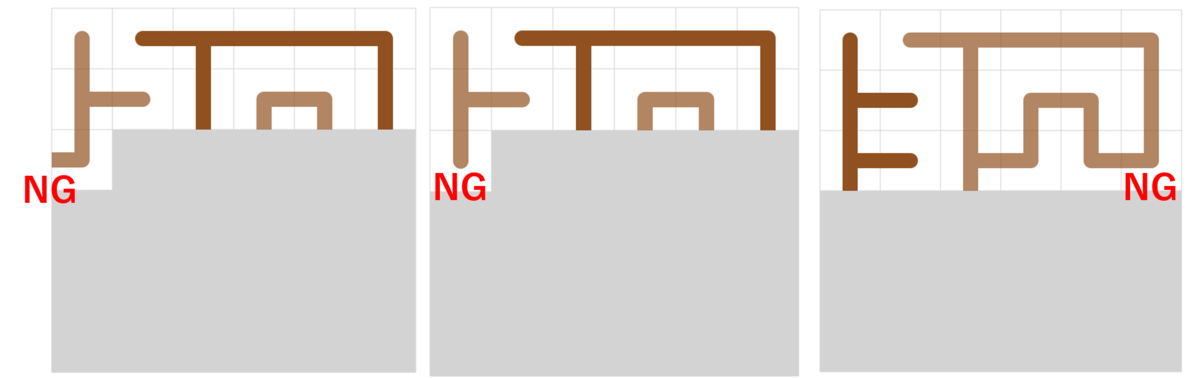
盤面を左上から順に乱拓 DFS でタイルを埋めて木を作る際に枝刈りするために、木になるための必要条件を考えました。
まず、線がタイルや盤面の境界で切れてはいけないことがまず考えられます。こちらは、毎回タイルを置く際にチェックすることが容易です。
次に、サイクルがないこと,非連結にならないことが必要条件で考えられます。
これらについては、第一実装では巻き戻し操作ありの Union-Find (My-Algorithm/UnionFind_reverse.hpp at master · kopricky/My-Algorithm · GitHub) を使うことで対応しました。この段階では、盤面に非連結な孤立した木がないかは1段全て埋めるごとに確認していました。
乱拓 DFS では、テキトーに残っているピースからランダムに選択することを行い、各箇所について 7 回までチャレンジして無理だったら 1 つ前の箇所に戻るようにしました(※戻る操作の際に Union-Find の巻き戻しを行います)。
このようにして、試しに実装してみると、高速に盤面を見つけられることが分かりました!これで少なくとも完全解は出来そうです。
固定した盤面を生成する操作列を作る
最終盤面を固定した場合に、どうやってそれを達成するかを考える必要がありました。
第一実装では下図のように番号付けすることで、 のスライドパズルと見なすことにしました。
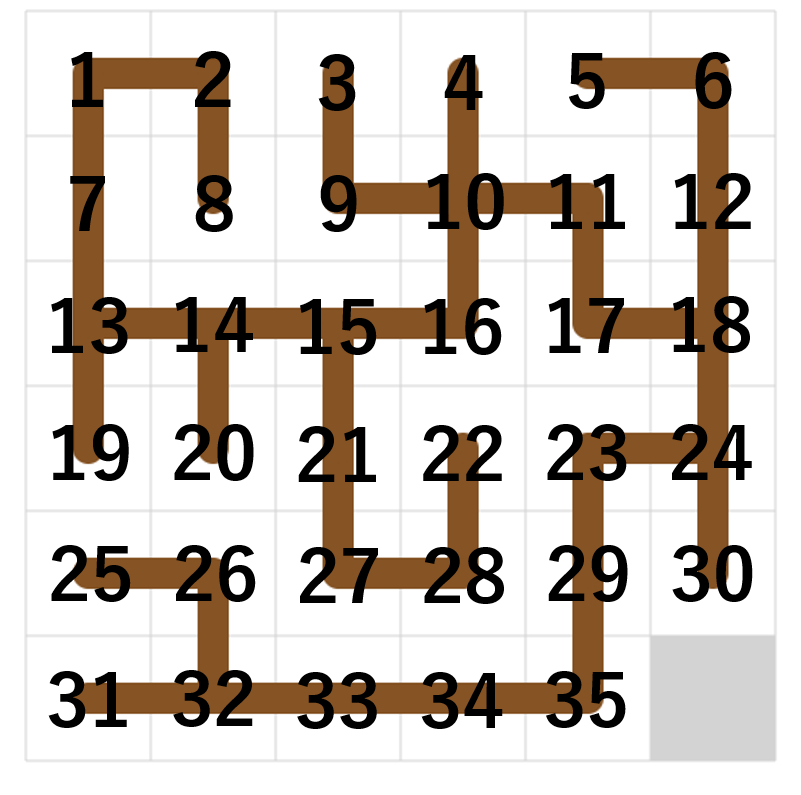
初期盤面で番号を振る必要があり、各タイルについて最終盤面とのユークリッド距離の総和が小さくなるようにしたいので、最小重みマッチングで決めました。このとき、パリティ条件が合わない場合はテキトーに同種の 2 つのタイルについて番号を swap しました。
のスライドパズルが解ければ良いところまで来ました。
貪欲に揃えることを考えたくなりますが、テキトーな順で 1 枚ずつ揃えようとすると、例えば上図で 1~5 まで揃えたときにどうやって 6 を埋めるかみたいな話がかなり面倒に見えました。
そこで、(1,2), (3,4), (5,6)... のように 2 枚ずつ埋めることにしました(ただし、 が奇数の時や最下部などは端からいい感じに置けるような順にしました)。
2 枚ずつ埋めるのは ( 1 枚目のタイルの位置,2 枚目のタイルの位置,空のマスの位置) の 3 つを管理する BFS で最短路とその経路を計算することが可能です。
また が奇数の場合、右下の
については最後まで放置して計算することにしました(
の状態を持つ最短路計算)。
以上を実装して提出したところ、35,937,271 点で(4 位, 2日目時点)でした。
(いい感じだ~と思いながらも、周りもどんどん上がっていくんだろうなと恐怖していました)
第二実装:盤面をピースに分けて貪欲に作る ~表引き編~
次の実装でも、第一実装と同じく、盤面を決定->操作列を決定 の順で構築しました。
盤面を決定するところでは、非連結判定の枝刈りをより強くしました。
その時点でまだ埋めていない場所に隣接し、かつ線が埋めていない場所に伸びているような場所を管理することで、1枚置くごとに非連結判定ができるようにしました。
最も大きな変更は操作列を決定する箇所です。
第一実装では毎回 BFS で操作列を計算しましたが、あらかじめ表を作ることで、毎回の計算をしなくて済むようになり高速化できます。
まず、最初に下図 ( の例) のように盤面を複数枚のタイル(ピースと呼ぶ)ごとに分割します。
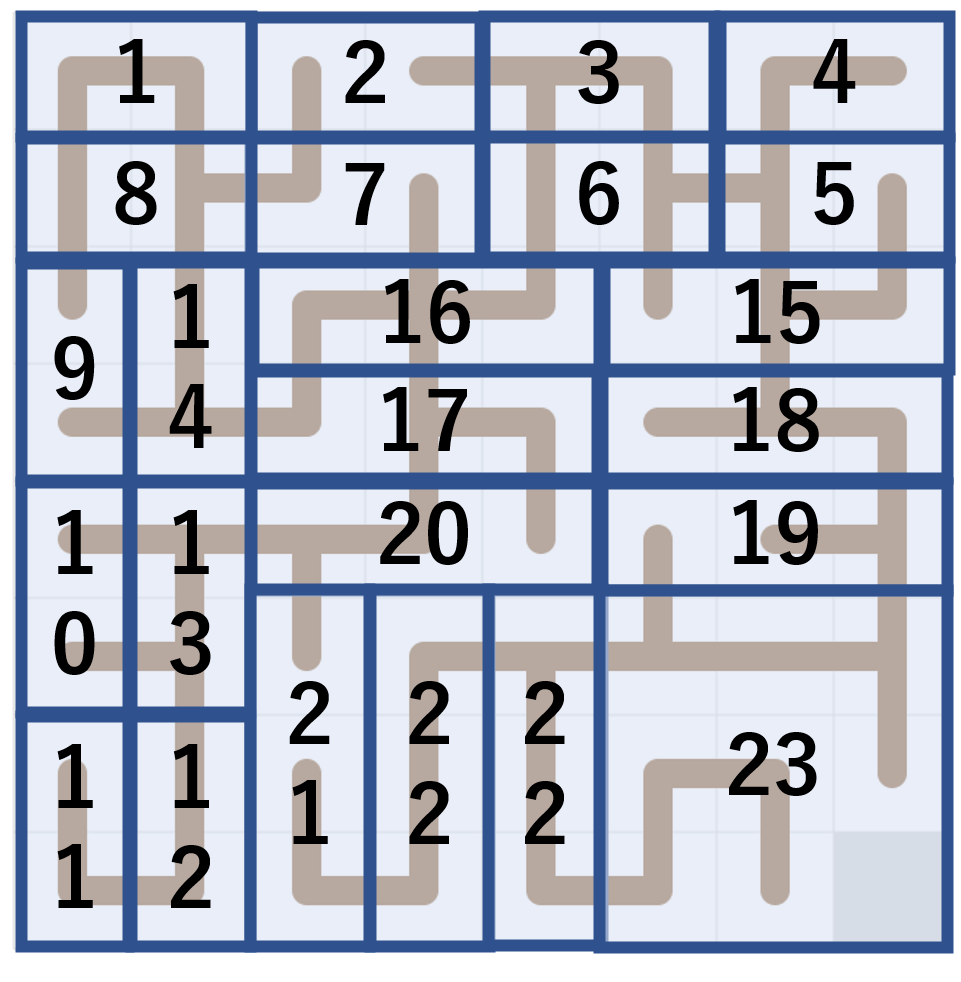
dp[何個目のピースを埋めているか][動かすタイル集合の位置][空白の位置] = (動かすのにかかる最短手数,次に動かす方向) とすると、これは BFS と同様に計算が出来ます。
ただし、表が持てるサイズならば3枚,4枚も同時に動かすことにしました。

第一実装では先に各タイルに番号を振っていましたが、それをやめて、最も最短手数が短いようなタイル集合を毎回動かすことに変えました。
ただし、 が偶数の場合は右下の
になったら、
が奇数の場合は右下の
になったら、パリティ条件を満たすように番号を振りました。
以上を実装し、制限時間一杯まで「盤面を決定->操作列を決定」を繰り返し最短なものを答えとすると、40,524,660 点 (6日目時点) と大台の 40M を超えることが出来ました。
第三実装:ビームサーチを導入する ~初めてのビームサーチ~
第二実装を終えた段階で、これを高速化してもあまり性能は出なさそうという気がしたので、新たなフレームワークを導入することにしました。
ビームサーチの亜種 (chokudai サーチと呼ばれる?) を使って、盤面の決定と操作列の決定を同時に探索することにしました。
(ビームサーチに関しては tsukammo さんの記事 競技プログラミングにおけるゲーム木探索の面白さ - Qiita を参考にさせていただきました)
状態としては、
(現在の手数, 現在の操作列,現在の決めた盤面,union-findの情報,その他諸々)
を管理して、現在の手数を比較のためのキーとして用いて、盤面と操作列を同時にビームサーチしました。
このとき、第三実装で定めたピースごとに盤面を決定し、操作列を第三実装と同様の貪欲で決定しました。また、各状態からはランダムに 6 通りまで有効な遷移先へと遷移することにしました。
これを実装したところ効果は絶大で、43,134,292 点 (7日目時点) と第三実装と比較して 3M も増加することが出来ました。
第四実装:要らない情報は持たない ~そして限界切り詰めバトルへ~
最後に、高速化してビームサーチの幅を増やすために、無駄な情報を状態として持たないように変更を加えました。
最終的に持った状態は
(現在の手数,残りの各タイルの枚数,操作列,現在の盤面,フロンティアの情報)
となりました。
ここで、フロンティア法と同様のテクニックを用いました。 *1
もう少し丁寧に説明すると、下図のように、まだ置いていない場所に線が伸びているようなタイルについて、連結成分の番号を保持します。この番号をタイルを置くごとに更新していきます。
このようにすると、次の図のように、サイクルを検出できます。
(同様に、非連結な孤立した木が出来てしまっているかなども判定できます。)
これにより、UnionFind の情報を持つのは不要になり、持つ情報を減らすことが出来ました。
その他の高速化として、周りの接続の状況を考えると、盤面に置くタイルの候補は高々4 通りしかないので、乱拓をする際にその 4 通りから選ぶように変更しました。
以上の高速化を加えて、各状態からの遷移を 10 通りまで選ぶことにすると、 43,499,848 点(5 位, pretest 時点)となりました。
結果:
最初に述べたように、システムテストの結果は 6 位でした。
点数の分布は以下のようになっていました(<=780000 のところは全て出力が上手く行っていないケースで、何も出力していません)

AHC011 - Sliding Tree Puzzle - Statistics を参考にさせていただくと、 のケースでは全体 3 位でかなりいい感じのようでしたが、最後まで戦っていた
などの小さいケースではあまりスコアが伸びていませんでした。
上位は焼きなましをしていた(?)ようなので、そのあたりで大きく差をつけられたようです。
特に、最後の 30 分で、出力が間に合っていないケースなどが見つかり、途中結果を出力するかしないかだけで順位を1つ落としたように見えたのが一番残念でした。
ただ、長期コンテストで 6 位は望外な結果なので嬉しかったです。
問題も最後まで面白く取り組めて楽しかったです。
知見と反省点:
最後に今回初めて知ったことや感じたことなどをまとめておきます。
- 最終提出までに、 1000 ケースくらいやって生成してテストしておくべきだった(100ケースでチューニングすると落ちるケースに気づけない)
- パラメータ調整は不十分だった。手元で調整するための環境を整えるべき。
- AtCoder のジャッジは手元より遅いので時間計測はかなり気をつけないといけない。
- 大量にメモリを vector などで確保するとメモリ解放に時間がかかって TLE することがある (200 msくらいかかることもあった)。
- 初手乱拓 DFS は結構良い、ビームサーチも実装してみるもんだ
- 長期コンはとにかく何でもかんでも実装した方が良い(実装したくないという心との戦い)
- 焼きなましはやっぱり強い
*1:フロンティア法は、数え上げお姉さんで有名な Zero-suppressed Binary Decision Diagram (ZDD) という列挙に強いデータ構造を構築する手法として知られています(解説スライド: https://hs-nazuna.github.io/tdzdd-manual/fbs-inst.pdf)。競プロ文脈だと ZDD が絡まない場合にも表現として使われますが、正しい表現なのかは私にはよく分かりません ( ZDD 関連で修論を書いたのに・・・)。